

Hashing is a fundamental concept in computer science and is used in various applications, from data storage to cryptography. In this blog, we will explore the basics of hashing, its advantages, and the different types of hash functions. Additionally, we will discuss some of the popular applications of hashing.
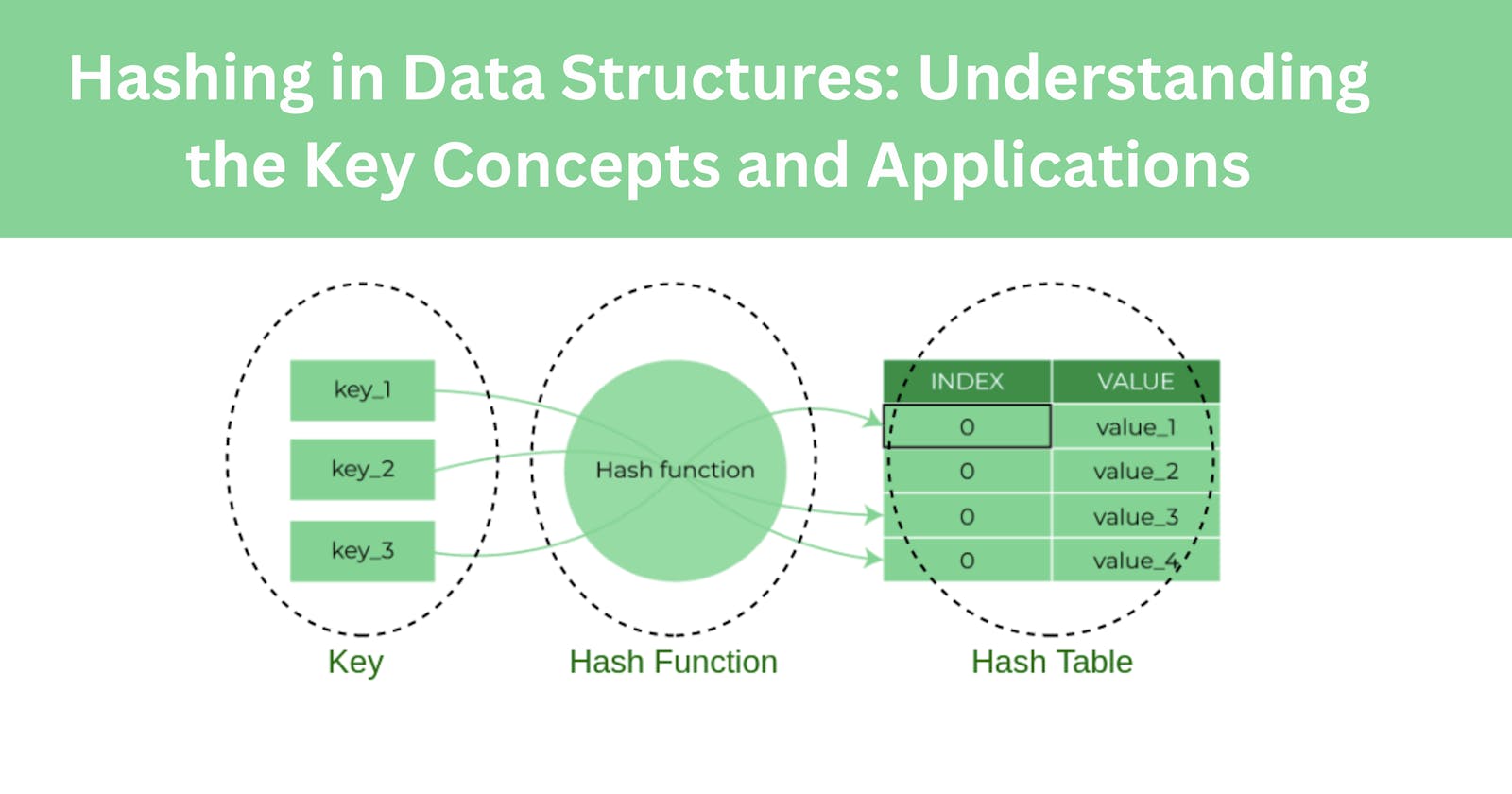
What is Hashing? Hashing is the process of mapping data of arbitrary size to a fixed-size output. This fixed-size output is called a hash or a message digest. The hash function takes input data and produces a fixed-length output, which is typically a unique representation of the input data. The resulting hash is often used for indexing, searching, and data integrity verification.
Advantages of Hashing: Hashing provides several advantages, such as:
Data Integrity Verification: Hashing is widely used for verifying data integrity. By comparing the hash value of the original data with the hash value of the received data, one can determine whether the data has been modified or corrupted during transmission.
Fast Retrieval: Hashing allows for quick retrieval of data from large datasets. Instead of searching through the entire dataset, hash functions can be used to index data and retrieve it quickly.
Security: Hashing is an essential tool in cryptography. It is used to store passwords securely and to authenticate data.
Types of Hash Functions: There are various types of hash functions, including:
Cryptographic Hash Functions: Cryptographic hash functions are designed to be secure and are commonly used in cryptography. Examples of cryptographic hash functions include SHA-256 and SHA-512.
Non-Cryptographic Hash Functions: Non-cryptographic hash functions are used for indexing, searching, and data integrity verification. Examples of non-cryptographic hash functions include MurmurHash and FNV.
Applications of Hashing: Hashing has several applications, including:
Password Storage: Hashing is used to store passwords securely. When a user enters a password, it is hashed and compared with the stored hash value. If the values match, the user is granted access.
Data Integrity Verification: Hashing is used to verify the integrity of data during transmission. The hash value of the original data is compared with the hash value of the received data to determine whether the data has been modified or corrupted.
Indexing and Searching: Hashing is used to index and search large datasets quickly. Hash functions can be used to map data to a fixed-size index, allowing for fast retrieval of data.
In Hashing Hash Tables are used but many times collision occurs when new data is being added to the Hash Table to avoid this there are many collision resolution techniques like linear probing, separate chaining and quadratic probing below there is an in-depth explanation of these techniques -
Linear Probing: Linear probing is a simple method for resolving collisions. When a collision occurs, the algorithm checks the next available slot in the table and places the item there. This process continues until an empty slot is found. The main disadvantage of linear probing is that it can result in clustering, where items are stored in adjacent slots, making it more difficult to search the table efficiently.

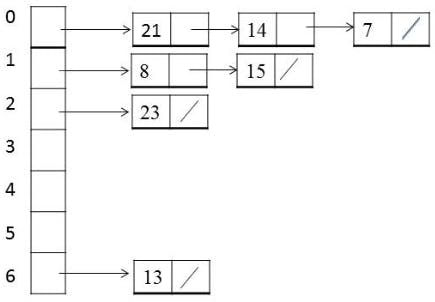
Separate Chaining: Separate chaining is a technique where each slot in the hash table contains a linked list of items that hash to that location. When a collision occurs, the item is added to the linked list. This method avoids clustering and is more efficient for large datasets. However, it requires additional memory to store the linked lists and may result in slower search times if the lists become too long.
Quadratic Probing: Quadratic probing is a variation of linear probing that tries to distribute items more evenly across the table. Instead of checking the next available slot, the algorithm searches for the next available slot using a quadratic function. This method reduces clustering and provides better search efficiency than linear probing. However, it may result in longer search times for some inputs.

In conclusion, hashing is an essential concept in computer science, providing several benefits such as data integrity verification, fast retrieval, and security. Understanding the different types of hash functions and their applications can help developers make informed decisions when implementing hashing in their applications.